





À partir d'iOS 13, les développeurs pourront ajouter dans leurs applications une fonction d'OCR, de la reconnaissance de caractères à partir d'une image, fournie par Apple.
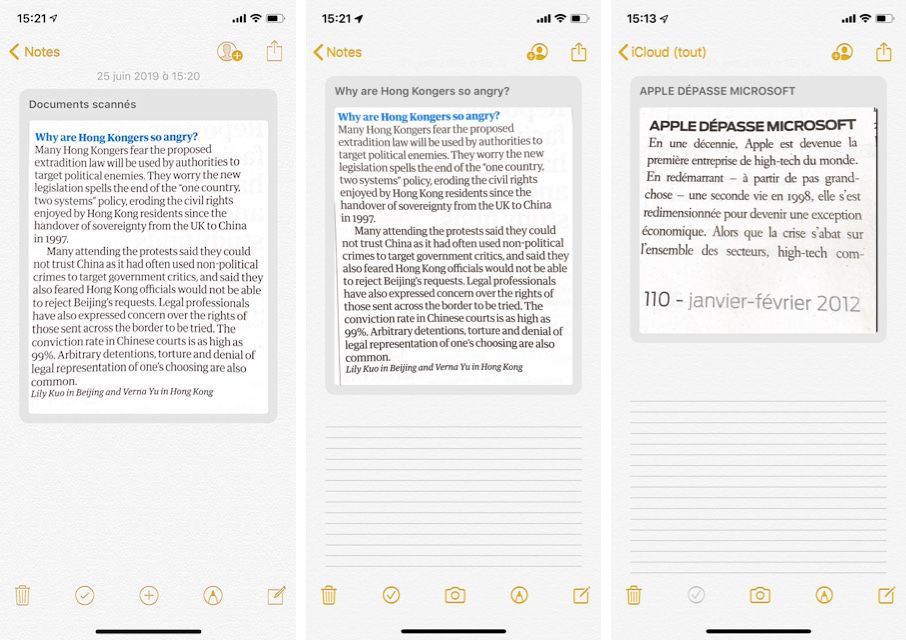
Depuis deux ans dans Notes, on dispose d'une fonction de scanner avec laquelle on peut photographier une carte de visite, un panneau, un bloc de texte dans une page, le détail d'une addition, etc. iOS détecte cet élément dans l'image et, même s'il est photographié de biais, il sait le plus souvent corriger la perspective pour le redresser et en améliorer la présentation en uniformisant l'éclairage.
Sur iOS 13, Apple a amélioré cette fonction en la dotant d'une reconnaissance de caractères. Elle propose le framework VisionKit contenant l'API Document Camera que tous les développeurs peuvent utiliser. Ce framework assure le gros du travail d'analyse de l'image et de reconnaissance du texte, déchargeant les développeurs d'une bonne partie de cet effort.
Lors de la présentation de VisionKit à la WWDC 2019, les deux ingénieurs d'Apple venus décrire son fonctionnement n'ont pas trop insisté sur la question de la langue, mais il a été dit que seul l'anglais était utilisé pour le moment [vidéo].
Ce que le nouveau Notes sait faire, des apps utilisant cette API en seront capables aussi. Dans iOS 13, lorsqu'un contenu texte a été scanné, Notes utilise automatiquement les premiers mots pour les affecter au titre de la note créée. Dans iOS 12, toutes ces notes portaient un nom générique de "Nouvelle note" et le scan était marqué comme "Document scanné". C'est du temps de gagné.
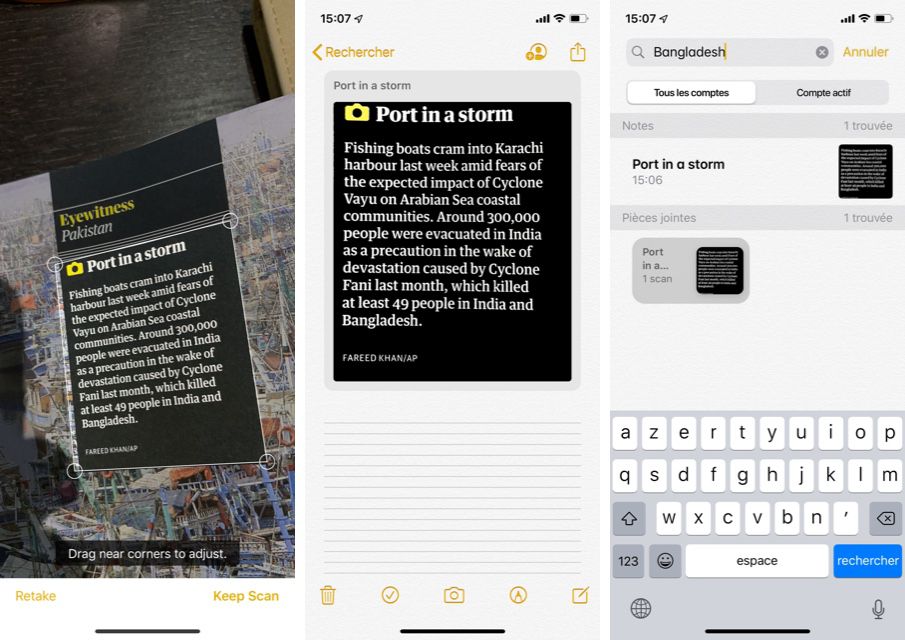
Cet OCR ouvre la voie à une fonction de recherche sur les contenus plus complète, puisqu'on peut retrouver un mot dans une image. Ici le nom du cyclone "Fani" a été indexé après qu'on ait photographié, un peu de travers, une légende (en anglais) dans un hebdo. Ça va même plus loin puisqu'iOS 13 sait parfois comprendre ce qu'il y a dans l'image, et permet de le retrouver par une recherche texte (ce sera par exemple la photo d'un avion sur une couverture, lire iOS 13 : toutes les nouveautés dans Notes).
Par contre le scan d'un texte en français ne donnera rien avec la recherche de texte, sauf exception lorsque le document contient des mots anglais ou des termes existant dans les deux langues.
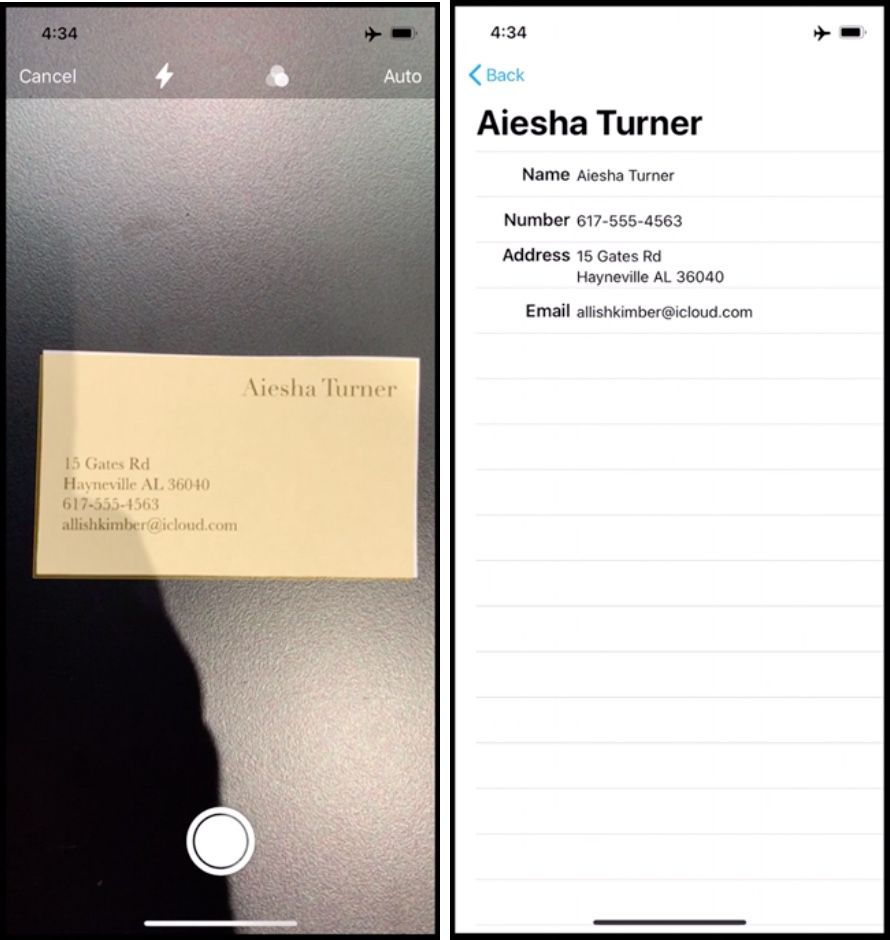
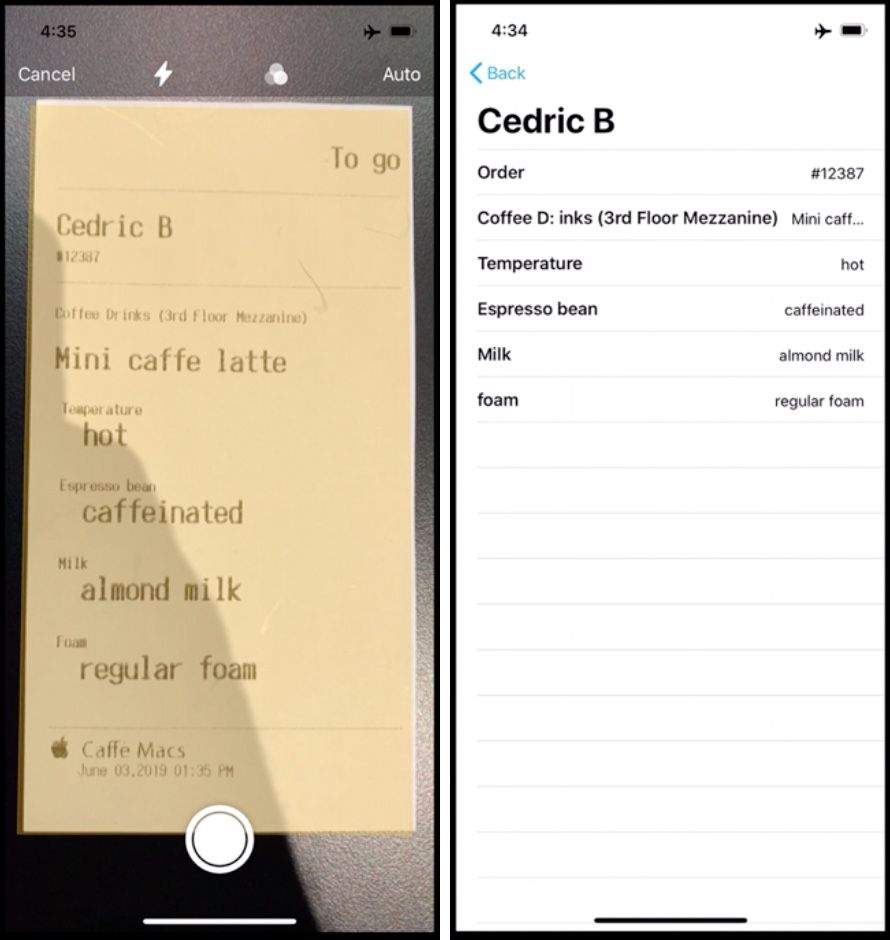
La possibilité suivante qui s'offre aux développeurs est d'extraire le texte reconnu et de le présenter sous une forme éditable toute bête ou de le reformater. Le nom, l'adresse et le numéro de téléphone pris dans une carte de visite pourront être affectés à des champs ad-hoc ou injectés dans un tableau. Tout dépend de ce que le développeur entend proposer avec son app.
La démonstration par les deux ingénieurs d'Apple a abordé les bonnes pratiques dont les développeurs seraient avisés de s'emparer, comme de décider s'ils ont besoin d'une reconnaissance rapide (qui utilisera le CPU de l'iPhone) ou plus précise mais plus longue (qui s'appuie sur les capacités de calcul de la puce graphique). C'est une affaire de contexte, la reconnaissance d'un code barre n'a pas besoin de beaucoup de puissance, alors autant laisser le GPU vaquer à des tâches plus importantes ou urgentes.

Ce point est néanmoins important car cette opération d'OCR est effectuée en local, directement sur le téléphone. Il n'y a pas d'aller et retour de l'image de votre document vers les serveurs d'Apple, comme le fait Microsoft avec son système d'OCR dans OneNote et que des développeurs tiers utilisent comme service intégré à leurs apps.
Si l'app et la fonction d'OCR visent un public particulier, comme des catégories de professionnels, il y aura tout intérêt à doter son app d'un lexique adapté, avec les spécificités de vocabulaire, insiste Apple.
Autre conseil, celui de proposer une reconnaissance où l'on n'embête pas l'utilisateur en lui demandant d'abord ce qu'il veut scanner comme type de document : un seul bouton "Scanner" plutôt qu'un choix entre "Scanner un reçu", "Scanner une carte", "Scanner autre chose"… Charge à l'app de se débrouiller pour identifier le document qu'on lui présente.






